IT之家 1 月 29 日消息,新年之际,阿里云公布了其全新的通义千问 Qwen 2.5-Max 超大规模 MoE 模型,大家可以通过 API 的方式进行访问,也可以登录 Qwen Chat 进行体验,例如直接与模型对话,或者使用 artifacts、搜索等功能。

据介绍,通义千问 Qwen 2.5-Max 使用超过 20 万亿 token 的预训练数据及精心设计的后训练方案进行训练。
性能
阿里云直接对比了指令模型的性能表现(IT之家注:指令模型即我们平常使用的可以直接对话的模型)。对比对象包括 DeepSeek V3、GPT-4o 和 Claude-3.5-Sonnet,结果如下:
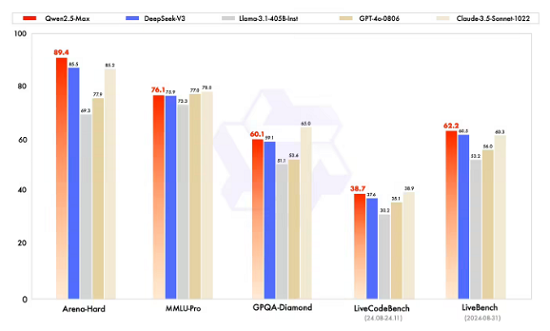
在 Arena-Hard、LiveBench、LiveCodeBench 和 GPQA-Diamond 等基准测试中,Qwen2.5-Max 的表现超越了 DeepSeek V3,同时在 MMLU-Pro 等其他评估中也展现出了极具竞争力的成绩。
在基座模型的对比中,由于无法访问 GPT-4o 和 Claude-3.5-Sonnet 等闭源模型的基座模型,阿里云将 Qwen2.5-Max 与目前领先的开源 MoE 模型 DeepSeek V3、最大的开源稠密模型 Llama-3.1-405B,以及同样位列开源稠密模型前列的 Qwen2.5-72B 进行了对比。对比结果如下图所示:
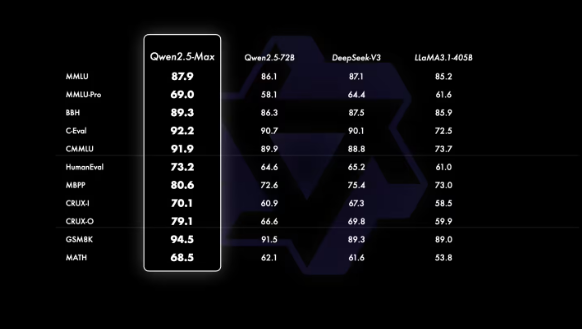
我们的基座模型在大多数基准测试中都展现出了显著的优势。我们相信,随着后训练技术的不断进步,下一个版本的 Qwen2.5-Max 将会达到更高的水平。
文章来源:IT之家 - 问舟


















